Yolov5环境搭建(详细过程)
本文最后更新于 2024年9月7日 下午
这是我在用Yolov5做目标检测时的环境搭建过程以及训练的模型过程。
先把参考连接放这: Yolov5训练自己的数据集(详细完整版)
然后环境的话就用Anaconda安装pyhton3.9就行
1. 安装Anaconda
Anaconda是一个用于科学计算的Python发行版,包含了众多科学计算相关的库。Anaconda提供了包管理器和环境管理器,可以方便地安装、更新和卸载Python包,
并且可以创建多个独立的环境,每个环境可以包含不同版本的Python和不同的包,方便进行多项目的管理和隔离。详细的安装步骤可以参考这个教程
Anaconda超详细安装教程(Windows环境下)
2. 创建虚拟环境
在Anaconda中,可以使用conda命令创建虚拟环境。虚拟环境是一种隔离的环境,可以在其中安装和管理Python包,而不会影响系统级别的Python环境。
1 | |
也可以在Anaconda的GUI界面中创建虚拟环境:
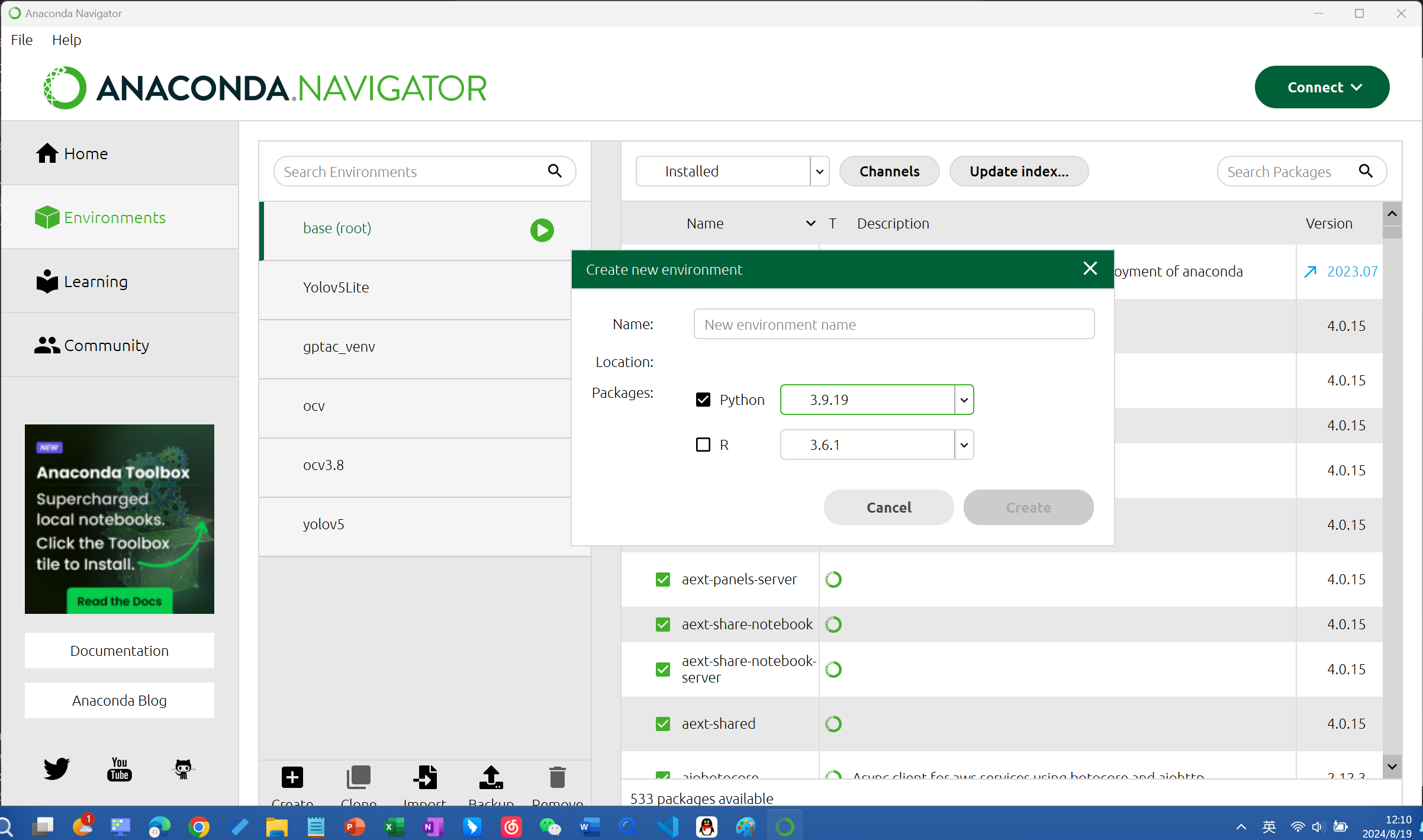
然后在终端中激活虚拟环境,后面在终端中进行的操作都是在你虚拟环境中进行的
1 | |
3. 下载yolov5
用Git下载yolov5代码,我这里也放个百度网盘链接(里边还有我收集好的数据集)提取码:6666
1 | |
4. 在yolov5目录下和对应虚拟环境中安装依赖
在文件资源管理器进入yolov5目录,打开终端(输入cmd),输入以下命令安装依赖:
激活对应的虚拟环境后输入下面的命令安装依赖:
1 | |
1 | |
5. 训练自己模型前的准备工作
5.1 准备数据集
具体参考我收集好的数据集(MyData文件夹):
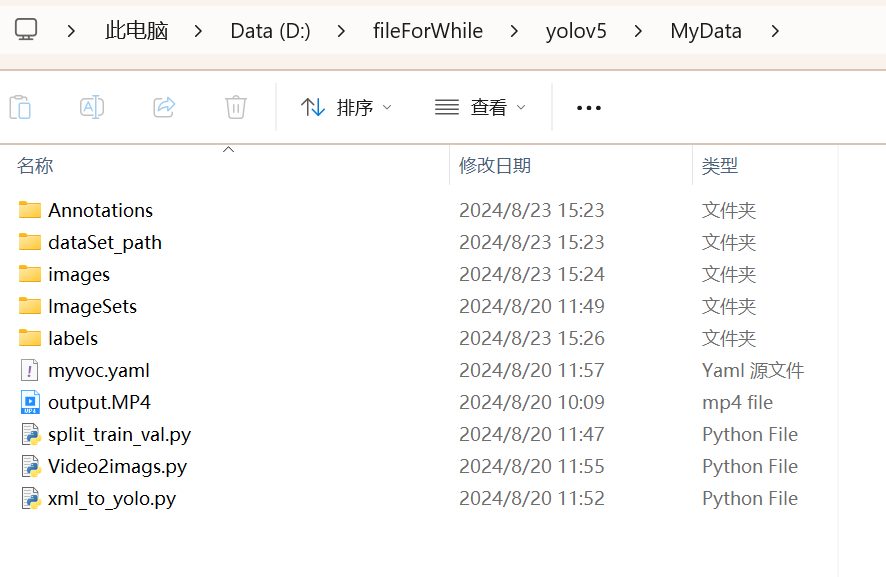
5.1.1 创建文件夹:Annotations和images
先创建MyData文件夹(也可以起其他名字),然后在里面创建两个文件夹: Annotations文件夹用来存放标注文件,images文件夹用来存放图片(这两个文件夹的名字一定是这俩) 创建标注文件需要我们安装一个python脚本,labelImg 下载地址,这里我们直接在刚创建的虚拟环境中安装就行: 首先激活我们的虚拟环境:
然后安装labelImg:
1 | |
安装好以后我们运行它:
1 | |
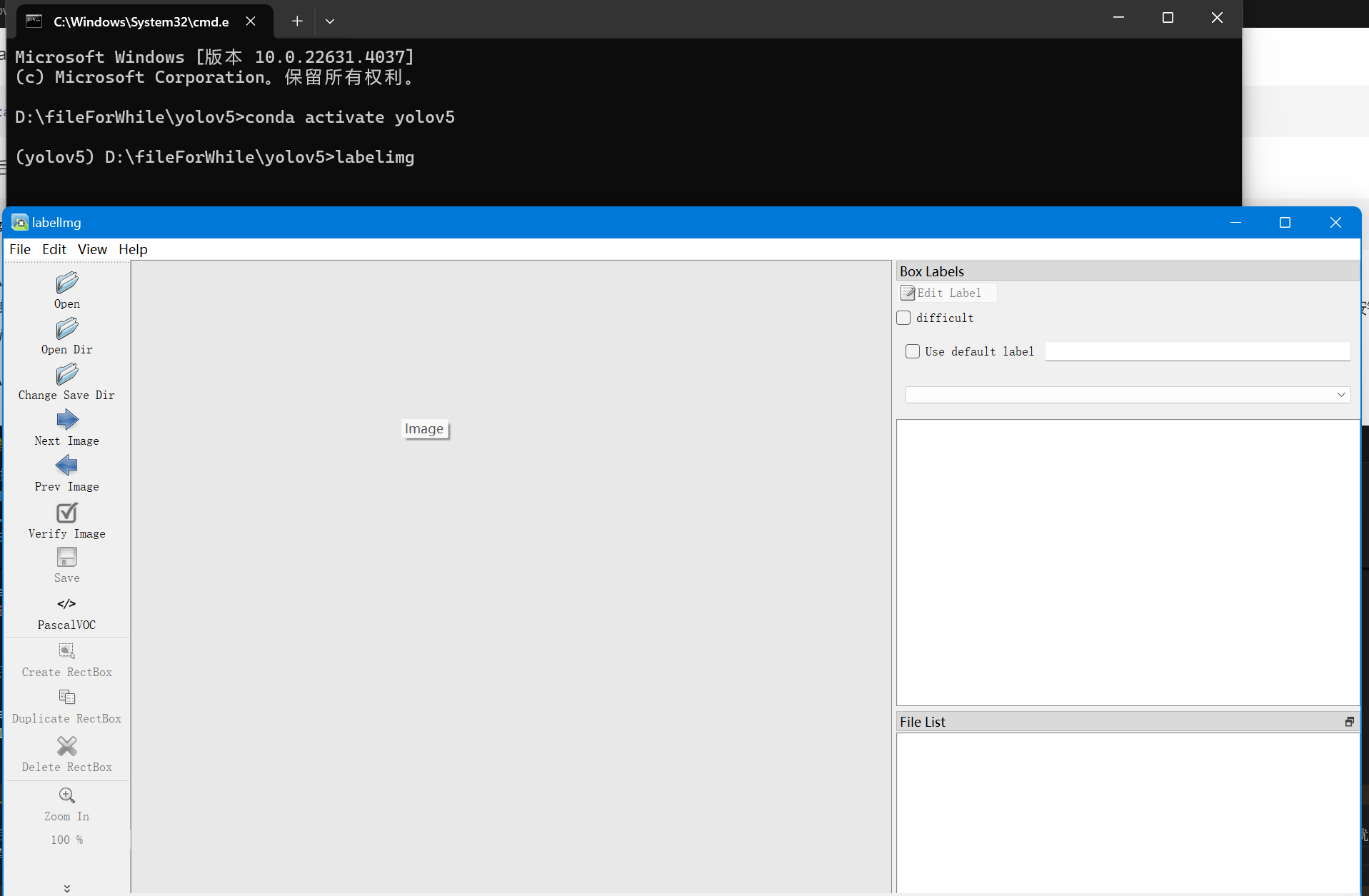
运行后会弹出一个窗口,我们点击Change save directory选择我们刚才创建的Annotations文件夹,然后点击Open Dir选择我们刚才创建的images文件夹,然后点击Create RectBox按钮,就可以开始标注了。
这里有个tip:按w标注,a上一张,d下一张。为了方便,记得打开自动保存
当然几百张照片,一张一张下载挺麻烦的,我这里有一个脚本Video2imags.py能够实现视频转图片:
1 | |
1 | |
要安装opencv库的同学看这里:
1 | |
有了图片,就可以开始我们的标注了,注意尽量贴合目标进行标注。
5.1.2 准备训练集和验证集
训练集用来训练模型,验证集用来评估模型的效果。我们需要把数据集分成训练集和验证集。这里我们运行split_train_val.py就可以自动帮我们生成训练集和验证集,
注意脚本里的一些代码需要根据你自己的需求来改(如果打开代码发现中文注释乱码就切换一下编码方式重新打开):
1 | |
1 | |
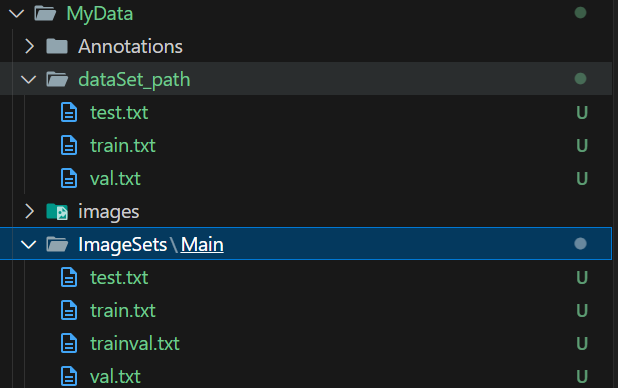
运行这个脚本会生成下面几个文件夹:dataSet_path,Images和Images下的Main,
Main里边有对应的txt文件
5.1.3 准备标签文件
标签文件是用来告诉模型我们要检测什么,我们需要一个txt文件。这里我们运行xml_to_yolo.py就可以自动帮咱生成,注意这个代码要把路径改成自己的数据集路径,还有你的类别要改成自己的。
1 | |
1 | |
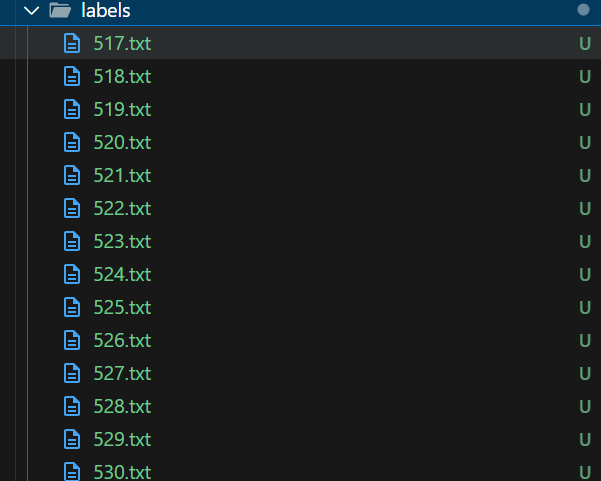
运行这个脚本会生成labels文件夹,里面有我们需要的txt文件。
5.1.4 准备配置文件
创建一个txt文件,名字叫myvoc.txt,将后缀修改为yaml,在记事本中进行编辑,内容如下:
1 | |
6. 训练模型
6.1 训练自己的数据集
我们需要训练自己的模型,这里我们运行train.py就可以训练我们的模型:
1 | |
参数解释
--weights:指定预训练权重,这里我们使用的是yolov5s.pt,如果没有下载,你运行后它会自己下载的--cfg:指定模型配置文件,这里我们使用的是yolov5s.yaml--data:指定数据集配置文件,这里我们使用的是myvoc.yaml。这个要改成你自己的配置文件路径。--epoch:指定训练的轮数,这里我们设置为200。训练200次--batch-size:指定训练的batch size,这里我们设置为8。训练8张图片后进行权重更新--img:指定训练的图片大小,这里我们设置为640。--device:指定训练的设备,这里我们设置为cpu。当然cpu会比较慢而且如果你cpu不咋行会报一些错,如果可以建议用GPU训练。
6.2 使用GPU训练
使用GPU训练需要你安装pytorch,这边直接放参考链接吧: 安装PyTorch详细过程
注意还是在我们的虚拟环境yolov5中安装的,装好以后运行train.py的参数中将--device cpu
改成--device 0即可。
6.3 训练结果检验
训练结束以后我们在runs\train\exp\weights下可以看到两个文件best.pt和last.pt,best.pt是我们训练的最佳权重,last.pt是我们训练的最后一次权重。
我们可以用
1 | |
来测试一下我们的模型效果。
参数解释
--weights:指定训练好的权重,这里我们使用的是runs/train/exp6/weights/best.pt--source:指定测试的视频或者图片路径,这里我们使用的是MyData/output.MP4
7. 总结
至此,我们已经完成了yolov5的环境搭建、数据集的准备、训练模型、测试模型等一系列操作。
yolov5是一个非常强大的目标检测模型,它可以检测出很多种类别的目标,而且它的速度也非常快,可以应用于各种场景。
而yolov5移植到树莓派上实现使用摄像头对目标的检测,我刚开始是这样想的,在树莓派上安装minianaconda,然后搭建一个和windows一样的虚拟环境,装好需要的
依赖,然后在树莓派上运行detect.py文件就好了,但实际上树莓派是linux操作系统,直接运行Windows系统上跑出来的模型是不行的好像。后边我才知道,原来yolov5
还有一个export.py脚本,可以将训练好的模型导出为ONNX格式,这样就可以在树莓派上运行了。并且在树莓派上安装4.5以上的opencv就可以用实现了。
要用export.py导出ONNX格式的模型,我们需要先安装onnx库,然后运行export.py脚本,命令如下:
1 | |
1 | |
更具体可以去看b站这个视频:树莓派:YOLOV5目标检测-模型训练与移植,获取这个视频里的代码YuHong-LDU/Python-RaspberryPI - Gitee.com
然后下面是树莓派上运行的代码,是上边那个视频里的,但视频里只演示了对单张图片的代码,下边这个是对视频或者摄像头的:
1 | |